
Eden CardimPublicado em 01/01/2010
"Mostre-me seus fluxogramas, esconda suas tabelas e eu continuarei
mistificado. Mostre-me suas tabelas e não precisarei dos seus fluxogramas,
eles serão óbvios"
-- Frederick Brooks - The Mythical Man-Month
"Entregar o produto é um dos requisitos"
-- http://www.jamesonwatts.com/2009/09/28/shipping-is-a-feature/
Bancos de dados relacionais tem sido a norma no desenvolvimento de aplicações de todos os tamanhos e tipos de complexidade a cerca de 30 anos. A combinação de um modelo com forte base científica e a vasta disponibilidade de literatura e ferramentas fazem com que as bases relacionais sejam uma escolha sólida para a maioria das aplicações em desenvolvimento. O paradigma de programação orientado a objetos, é relativamente bem menos popular e formal, mas também vastamente utilizado dentro do seu campo de aplicação. Pensar em termos de objetos e das interações entre eles é uma tendência natural para um ser humano e estabelece uma ponte entre a engenharia tradicional e o desenvolvimento de software. Bancos de dados relacionais e orientação a objetos são elementos da engenharia de software que vem sendo utilizados em conjunto por muito tempo. Esse artigo irá abordar as vantagens, desvantagens e apresentar o uso do DBIx::Class como solução para os problemas cotidianos dessa parceria tecnológica.
Objetos e Relações são conceitos de natureza fundamentalmente diferentes, apesar de apresentarem algumas similaridades deceptivas. A travessia entre objetos ocorre através de ponteiros e referências enquanto as relações são unidas através de produtos cartesianos e chaves estrangeiras, o que leva a soluções de otimização diferentes para ambos os casos. As operações de acesso também variam bastante a depender do volume de dados e relacionamentos envolvidos. Por exemplo, obter um único estudante dentre todos os estudantes de um determinado estado é uma operação diferente de obter o estudante com o melhor desempenho escolar. A implementação orientada a objeto presume que a informação é acessível de maneira uniforme. Também vale ressaltar que, ao contrário de registros em uma relação, objetos não são canônicos.
Durante o ciclo de vida de um projeto de software, ocorrem mudanças significativas em todas as camadas. Manter a integração entre os componentes de software é uma tarefa árdua e contínua. Uma simples mudança no nome de um campo requer que todas as referências ao nome desse campo sejam atualizadas na aplicação. Uma refatoração típica envolve muito mais do que renomear um campo, tabelas são criadas e removidas, chaves são alteradas para refletir as mudanças, e dados que antes viviam num único registro agora se encontram renormalizados entre várias tabelas e registros e todo o código da aplicação agora precisa ser atualizado para refletir as mudanças estruturais.
Ao longo dos anos, a principal técnica desenvolvida para atenuar os problemas com o acesso a dados é o encapsulamento da complexidade numa camada dedicada. Tipicamente, ela atua como embaixatriz entre o domínio da base de dados e o da aplicação e se ajusta para que alterações em qualquer um dos lados não impactue (muito) o outro.
Dentro do paradigma orientado a objetos, representar a camada de acesso a dados com um objeto que é responsável por consultar a base de dados e construir outros objetos a partir dos resultados é uma solução bastante óbvia e direta. Suponha um caso simples: construir boletins de alunos de ensino fundamental.
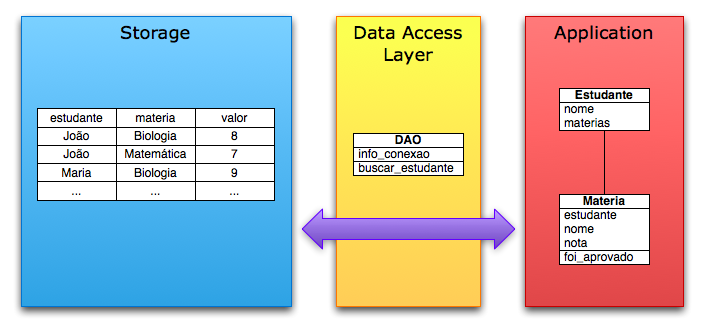
Primeiro, criamos o schema
CREATE TABLE nota (
estudante VARCHAR(255) NOT NULL,
materia VARCHAR(255) NOT NULL,
nota INT NOT NULL,
PRIMARY KEY (estudante, materia)
);
Populamos com alguns valores de teste:
INSERT INTO nota (estudante, materia, valor) VALUES ('João', 'Biologia', 8);
INSERT INTO nota (estudante, materia, valor) VALUES ('João', 'Matemática', 7);
INSERT INTO nota (estudante, materia, valor) VALUES ('João', 'Física', 6);
INSERT INTO nota (estudante, materia, valor) VALUES ('Maria', 'Biologia', 9);
Depois, um Data Access Object simples:
package DAO;
use Moose;
use DBI;
use Estudante;
use Materia;
has info_conexao => (
isa => 'ArrayRef',
is => 'ro',
auto_deref => 1,
required => 1
);
has _dbh => (isa => 'DBI::db', is => 'ro', lazy_build => 1);
sub _build__dbh { DBI->connect(shift->info_conexao) }
sub buscar_estudante {
my($self, $nome_estudante) = @_;
my $sth = $self->_dbh->prepare(<execute($nome_estudante);
my $result = $sth->fetchall_arrayref;
return unless @$result;
my $estudante = Estudante->new(nome => $nome_estudante, materias => []);
my @materias = map {
Materia->new(
estudante => $estudante,
nome => $_->[0], # campo: materia
nota => $_->[1]) # campo: valor
} @$result;
push @{$estudante->materias}, @materias;
return $estudante;
}
1;
E agora, as classes do lado da aplicação:
package Estudante;
use Moose;
has nome => (isa => 'Str', is => 'ro', required => 1);
has materias => (isa => 'ArrayRef', is => 'ro', required => 1);
1;
package Materia;
use Moose;
has estudante => (isa => 'Estudante', is => 'ro', required => 1);
has nome => (isa => 'Str', is => 'ro', required => 1);
has nota => (isa => 'Int', is => 'ro', required => 1);
sub foi_aprovado { shift->nota >= 7 }
1;
E finalmente, nosso teste:
use warnings;
use strict;
use Test::More qw(no_plan);
use DAO;
my $dao = DAO->new(
info_conexao => ['dbi:Pg:dbname=equinocio_students', 'edenc', '']
);
my $nome = 'João';
isa_ok(my $estudante = $dao->buscar_estudante($nome), 'Estudante');
cmp_ok(scalar @{$estudante->materias}, '==', 3);
isa_ok($_, 'Materia') for @{$estudante->materias};
is($estudante->nome, $nome);
my %nota_esperada = (Biologia => 8, 'Matemática' => 7, 'Física' => 6);
cmp_ok(
$_->nota, '==', $nota_esperada{$_->nome},
$_->nome . ' nota'
) for @{$estudante->materias};
my %aprovacao_esperada = (Biologia => 1, 'Matemática' => 1, 'Física' => 0);
cmp_ok(
$_->foi_aprovado, '==', $aprovacao_esperada{$_->nome},
$_->nome . ' aprovação'
) for @{$estudante->materias};
Rodamos o teste, e conferimos que está tudo ok:
prove -lv t/001-buscar-estudante.t
t/001-buscar-estudante.t ..
ok 1 - The object isa Estudante
ok 2
ok 3 - The object isa Materia
ok 4 - The object isa Materia
ok 5 - The object isa Materia
ok 6
ok 7 - Biologia nota
ok 8 - Física nota
ok 9 - Matemática nota
ok 10 - Biologia aprovação
ok 11 - Física aprovação
ok 12 - Matemática aprovação
1..12
ok
All tests successful.
Files=1, Tests=12, 1 wallclock secs ( 0.03 usr 0.02 sys + 0.25 cusr 0.03 csys = 0.33 CPU)
Result: PASS
O bom observador vai perceber algumas limitações nessa abordagem. Por exemplo, esse DAO não sabe criar nem atualizar objetos, dentre outras. Outra questão notável é falta de normalização na tabela, afinal de contas, é uma implementação ingênua. Suponha também que surgiu um requisito de última hora: os estudantes precisam ser agrupados em turmas, ser listados em ordem alfabética e as notas de um determinado estudante precisam estar ordenadas por matéria. Uma abordagem mais correta seria:
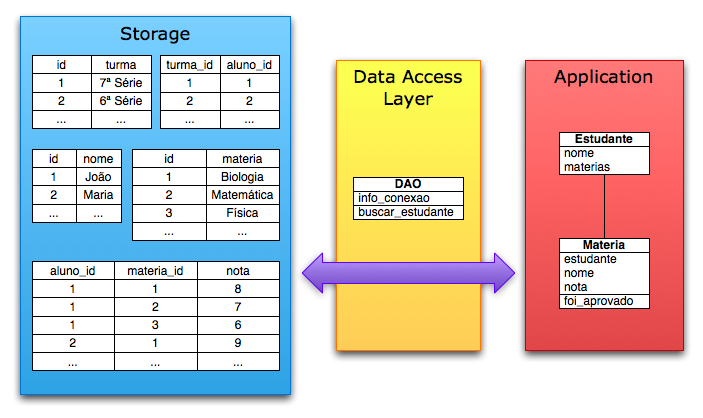
Um pouco de análise vai revelar que a API do DAO precisa ser repensada. Por exemplo, um método para realizar a listagem dos estudantes seria bastante similar ao método que obtém um estudante individual, basta omitir a restrição por nome. Outra porção de código que pode ser reaproveitada é a construção do objetos Estudante e Matéria. Vale ressaltar que operações como ordenação e agrupamento são mais eficientes se realizadas pelo próprio backend de storage. Se, por exemplo, for necessário exibir os 10 alunos com as melhores notas no país inteiro, fazer a ordenação no lado da aplicação geraria um overhead de memória proibitivo. A API do DAO também precisa ser cuidadosamente confeccionada para evitar a falácia comum de:
$dao->listar_estudantes
$dao->listar_estudantes_ordenados_por_nome
$dao->listar_estudantes_ordenados_por_nota
# etc...
O problema com essa abordagem é que quando for necessário ordenar estudantes por nome e nota, não vai ser possível reaproveitar os métodos existentes. Esse padrão de consultas combinadas é bastante recorrente durante a vida de uma aplicação. Fica claro que o principal problema na construção de um DAO é projetar uma arquitetura e API que chegue a um ponto de convergência útil para a aplicação, mesmo porque, se a API muda constantemente, a camada de acesso será inútil porque a aplicação terá que mudar também, para acomodar as mudanças na API. O mais correto em termos de contrato seria o DAO expor métodos que tenham sentido conceitual para a aplicação, por exemplo:
$dao->melhores_estudantes_nacionais
$dao->estudantes_aprovados
$dao->estudantes_por_serie('7ª Série')
# etc...
Dessa forma, os detalhes de implementação são encapsulados e a aplicação se preocupa apenas com as regras de negócio. Além disso, o observador muito cauteloso também irá perceber que não existe tratamento de erros a nível de infra-estrutura, como verificação de persistência da conexão com o banco de dados, pooling de conexões e relatório de erros.
O mapeamento objeto-relacional (popularmente conhecido como ORM - Object-Relational Mapping/Mapper) é uma tentativa de reaproveitar trabalho baseado nas similaridades entre os modelos orientado a objetos e relacional. Nem todas as soluções são felizes, e a maioria trazem mais problemas do que soluções. Muitos ORMs são baseados em convenções, ou seja, requerem que a modelagem e arquitetura da base de dados seja adequada ao caso para o qual o ORM foi projetado. Outros introspectam e refletem os campos das tabelas diretamente para atributos de objetos, o que significa que métodos de acesso para os atributos modificados magicamente deixam de funcionar em toda a aplicação. A maioria das convenções não permitem o uso de chaves compostas, o que reduz bastante a utilidade de ORMs em sistemas mais complexos. Muitos também substituem SQL por uma linguagem de mapeamento própria, o que adiciona um elemento de complexidade extra ao código. Em particular, DBA's que já são bastante proficientes com SQL se sentem menos confortáveis e são menos produtivos aprendendo uma linguagem específica e que tipicamente é menos flexível do que SQL. A arquitetura baseada em convenção também reduz a extensibilidade e customização dos sistemas, criando barreiras na hora de se realizarem otimizações específicas de domínio. Todos esses problemas tem criado uma certa aversão a ORMs entre os DBA's mais experientes.
Pensando em todos os problemas previamente mencionados, o DBIx::Class tenta adotar uma abordagem diferenciada. A principal regra é manter a flexibilidade provendo defaults sensatos. Os defaults permitem que as aplicações comecem a ser desenvolvidas rapidamente e as customizações podem ser acrescentadas ao longo do projeto. Pode-se dizer que o DBIx::Class está mais para um framework para projetos de DAO do que um ORM. Invés de mapear diretamente para classes da aplicação, são construidos objetos intermediários que facilitam a construção de objetos do domínio. Um sistema de meta-dados "ensina" esses objetos a interagirem com as tabelas, de acordo com o backend adotado.
Objetos Schema são o ponto de entrada para a camada de acesso a dados. A construção da classe é bem simples e direta:
package MySchema;
use warnings;
use strict;
use base qw/DBIx::Class::Schema/;
__PACKAGE__->load_namespaces;
1;
O método load_namespaces indica que queremos carregar as definições de
tabelas do local padrão que são os namespaces MySchema::Result e
MySchema::ResultSet. Essas definições podem ser escritas manualmente ou
introspectadas de uma base existente através do DBIx::Class::Schema::Loader.
Suponha o seguinte schema:
--
-- PostgreSQL database dump
--
SET client_encoding = 'UTF8';
SET standard_conforming_strings = off;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET escape_string_warning = off;
SET search_path = public, pg_catalog;
--
-- Name: aluno_id_seq; Type: SEQUENCE; Schema: public; Owner: edenc
--
CREATE SEQUENCE aluno_id_seq
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
ALTER TABLE public.aluno_id_seq OWNER TO edenc;
--
-- Name: aluno_id_seq; Type: SEQUENCE SET; Schema: public; Owner: edenc
--
SELECT pg_catalog.setval('aluno_id_seq', 2, true);
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: aluno; Type: TABLE; Schema: public; Owner: edenc; Tablespace:
--
CREATE TABLE aluno (
id integer DEFAULT nextval('aluno_id_seq'::regclass) NOT NULL,
nome character varying(255) NOT NULL
);
ALTER TABLE public.aluno OWNER TO edenc;
--
-- Name: aluno_materia; Type: TABLE; Schema: public; Owner: edenc; Tablespace:
--
CREATE TABLE aluno_materia (
aluno_id integer NOT NULL,
materia_id integer NOT NULL,
nota integer
);
ALTER TABLE public.aluno_materia OWNER TO edenc;
--
-- Name: materia_id_seq; Type: SEQUENCE; Schema: public; Owner: edenc
--
CREATE SEQUENCE materia_id_seq
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
ALTER TABLE public.materia_id_seq OWNER TO edenc;
--
-- Name: materia_id_seq; Type: SEQUENCE SET; Schema: public; Owner: edenc
--
SELECT pg_catalog.setval('materia_id_seq', 3, true);
--
-- Name: materia; Type: TABLE; Schema: public; Owner: edenc; Tablespace:
--
CREATE TABLE materia (
id integer DEFAULT nextval('materia_id_seq'::regclass) NOT NULL,
nome character varying(255) NOT NULL
);
ALTER TABLE public.materia OWNER TO edenc;
--
-- Name: turma_id; Type: SEQUENCE; Schema: public; Owner: edenc
--
CREATE SEQUENCE turma_id
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
ALTER TABLE public.turma_id OWNER TO edenc;
--
-- Name: turma_id; Type: SEQUENCE SET; Schema: public; Owner: edenc
--
SELECT pg_catalog.setval('turma_id', 2, true);
--
-- Name: turma; Type: TABLE; Schema: public; Owner: edenc; Tablespace:
--
CREATE TABLE turma (
id integer DEFAULT nextval('turma_id'::regclass) NOT NULL,
turma character varying(255)
);
ALTER TABLE public.turma OWNER TO edenc;
--
-- Name: turma_aluno; Type: TABLE; Schema: public; Owner: edenc; Tablespace:
--
CREATE TABLE turma_aluno (
turma_id integer NOT NULL,
aluno_id integer NOT NULL
);
ALTER TABLE public.turma_aluno OWNER TO edenc;
--
-- Data for Name: aluno; Type: TABLE DATA; Schema: public; Owner: edenc
--
INSERT INTO aluno (id, nome) VALUES (1, 'João');
INSERT INTO aluno (id, nome) VALUES (2, 'Maria');
--
-- Data for Name: aluno_materia; Type: TABLE DATA; Schema: public; Owner: edenc
--
INSERT INTO aluno_materia (aluno_id, materia_id, nota) VALUES (1, 1, NULL);
INSERT INTO aluno_materia (aluno_id, materia_id, nota) VALUES (1, 2, NULL);
INSERT INTO aluno_materia (aluno_id, materia_id, nota) VALUES (1, 3, NULL);
INSERT INTO aluno_materia (aluno_id, materia_id, nota) VALUES (2, 1, NULL);
--
-- Data for Name: materia; Type: TABLE DATA; Schema: public; Owner: edenc
--
INSERT INTO materia (id, nome) VALUES (1, 'Biologia');
INSERT INTO materia (id, nome) VALUES (2, 'Matemática');
INSERT INTO materia (id, nome) VALUES (3, 'Física');
--
-- Data for Name: turma; Type: TABLE DATA; Schema: public; Owner: edenc
--
INSERT INTO turma (id, turma) VALUES (1, '7ª Série');
INSERT INTO turma (id, turma) VALUES (2, '6ª Série');
--
-- Data for Name: turma_aluno; Type: TABLE DATA; Schema: public; Owner: edenc
--
INSERT INTO turma_aluno (turma_id, aluno_id) VALUES (1, 1);
INSERT INTO turma_aluno (turma_id, aluno_id) VALUES (2, 2);
--
-- Name: aluno_materia_pkey; Type: CONSTRAINT; Schema: public; Owner: edenc; Tablespace:
--
ALTER TABLE ONLY aluno_materia
ADD CONSTRAINT aluno_materia_pkey PRIMARY KEY (aluno_id, materia_id);
--
-- Name: aluno_pkey; Type: CONSTRAINT; Schema: public; Owner: edenc; Tablespace:
--
ALTER TABLE ONLY aluno
ADD CONSTRAINT aluno_pkey PRIMARY KEY (id);
--
-- Name: materia_pkey; Type: CONSTRAINT; Schema: public; Owner: edenc; Tablespace:
--
ALTER TABLE ONLY materia
ADD CONSTRAINT materia_pkey PRIMARY KEY (id);
--
-- Name: turma_aluno_pkey; Type: CONSTRAINT; Schema: public; Owner: edenc; Tablespace:
--
ALTER TABLE ONLY turma_aluno
ADD CONSTRAINT turma_aluno_pkey PRIMARY KEY (turma_id, aluno_id);
--
-- Name: turma_pkey; Type: CONSTRAINT; Schema: public; Owner: edenc; Tablespace:
--
ALTER TABLE ONLY turma
ADD CONSTRAINT turma_pkey PRIMARY KEY (id);
--
-- Name: aluno_materia_aluno_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: edenc
--
ALTER TABLE ONLY aluno_materia
ADD CONSTRAINT aluno_materia_aluno_id_fkey FOREIGN KEY (aluno_id) REFERENCES aluno(id);
--
-- Name: aluno_materia_materia_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: edenc
--
ALTER TABLE ONLY aluno_materia
ADD CONSTRAINT aluno_materia_materia_id_fkey FOREIGN KEY (materia_id) REFERENCES materia(id);
--
-- Name: turma_aluno_aluno_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: edenc
--
ALTER TABLE ONLY turma_aluno
ADD CONSTRAINT turma_aluno_aluno_id_fkey FOREIGN KEY (aluno_id) REFERENCES aluno(id);
--
-- Name: turma_aluno_turma_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: edenc
--
ALTER TABLE ONLY turma_aluno
ADD CONSTRAINT turma_aluno_turma_id_fkey FOREIGN KEY (turma_id) REFERENCES turma(id);
--
-- Name: public; Type: ACL; Schema: -; Owner: postgres
--
REVOKE ALL ON SCHEMA public FROM PUBLIC;
REVOKE ALL ON SCHEMA public FROM postgres;
GRANT ALL ON SCHEMA public TO postgres;
GRANT ALL ON SCHEMA public TO PUBLIC;
--
-- PostgreSQL database dump complete
--
O seguinte comando shell é o suficiente para iniciar:
perl -MDBIx::Class::Schema::Loader=make_schema_at -le'make_schema_at("MySchema", { use_namespaces => 1, dump_directory => "./lib" },
["dbi:Pg:dbname=equinocio_students", "edenc", ""])'
A opção use_namespaces indica que queremos prefixar nossas classes com
MySchema::Result:: e MySchema::ResultSet, que é a prática mais comum na
comunidade do DBIx::Class.
A opção dump_directory indica em qual diretório queremos criar as classes.
O array ["dbi:Pg:dbname=equinocio_students", "edenc", ""] são opções de
conexão com o banco de dados, tal qual seria passado ao DBI (como vimos na
pequena implementação de um DAO).
O diretório lib agora contém as classes com as definições introspectadas da
base de dados.
Para obter mais opções de customização, consulte a documentação do
DBIx::Class::Schema::Loader.
Objetos Result Source contém meta-dados sobre as tabelas, como o nome da
tabela, os nomes de colunas, restrições de unicidade e relacionamentos.
No arquivo lib/MySchema/Result/Aluno.pm temos o código introspectado pelo
DBIx::Class::Schema::Loader para a tabela aluno.
__PACKAGE__->load_components("Core");
Essa instrução carrega a infra-estrutura básica do DBIx::Class. Componentes
adicionais podem ser carregados aqui também.
__PACKAGE__->table("aluno");
table indica o nome da tabela que este Result Source está referenciando,
todas as consultas vão usar esse valor, literalmente.
__PACKAGE__->add_columns(
"id",
{
data_type => "integer",
default_value => "nextval('aluno_id_seq'::regclass)",
is_nullable => 0,
size => 4,
},
"nome",
{
data_type => "character varying",
default_value => undef,
is_nullable => 0,
size => 255,
},
);
add_columns indica os nomes e tipos de dados das colunas da tabela. Apenas
o nome da coluna é obrigatório, as demais informações não são necessárias para
a operação do DBIx::Class.
__PACKAGE__->set_primary_key("id");
set_primary_key indica a chave primária desta tabela. A declaração correta
da chave primária da tabela é essencial para o bom funcionamento do
DBIx::Class. Chaves compostas são suportadas normalmente (A tabela
MySchema::Result::AlunoMateria contém um exemplo).
__PACKAGE__->add_unique_constraint("aluno_pkey", ["id"]);
add_unique_constraint indica uma restrição de unicidade sobre uma tupla.
Declarações de unicidade facilitam a construção posterior de consultas.
__PACKAGE__->has_many(
"aluno_materias",
"MySchema::Result::AlunoMateria",
{ "foreign.aluno_id" => "self.id" },
);
has_many indica um relacionamento 1-N, nesse caso, um registro em aluno
pode ter vários registros relacionados na tabela aluno_materia. As duas
tabelas se relacionam através da chave estrangeira aluno_id na tabela
aluno_materia, indicada pelo prefixo foreign, e da chave primária id,
na tabela aluno, indicada pelo prefixo self.
Outros tipos de relacionamento, como belongs_to (N-1), has_one (1-1) e
might_have (1-1,0) são utilizáveis baseados na mesma semântica.
Relacionamentos N-M são um caso especial, é necessário dois relacionamentos
(1-N) em duas tabelas distintas com uma terceira tabela (a
tabela-relacionamento). Por conta da natureza abstrata desse tipo de
relacionamento, o instrospectador não consegue detectá-lo automaticamente.
A tabela AlunoMateria é um exemplo de tabela-relacionamento, o
DBIx::Class já criou os relacionamentos básicos. Observe que os
relacionamentos tem como nome as chaves primárias, atribuídas automaticamente,
para evitar confusão com o valor da coluna, é recomendável que se renomeie o
relacionamento:
--- lib/MySchema/Result/AlunoMateria.pm
+++ lib/MySchema/Result/AlunoMateria.pm
@@ -18,11 +18,11 @@ __PACKAGE__->add_columns(
__PACKAGE__->set_primary_key("aluno_id", "materia_id");
__PACKAGE__->add_unique_constraint("aluno_materia_pkey", ["aluno_id", "materia_id"]);
__PACKAGE__->belongs_to(
- "materia_id",
+ "materia",
"MySchema::Result::Materia",
{ id => "materia_id" },
);
-__PACKAGE__->belongs_to("aluno_id", "MySchema::Result::Aluno", { id => "aluno_id" });
+__PACKAGE__->belongs_to("aluno", "MySchema::Result::Aluno", { id => "aluno_id" });
# Created by DBIx::Class::Schema::Loader v0.04006 @ 2010-03-09 21:13:41
Falta unir as tabelas relevantes através da tabela-relacionamento.
Aluno:
--- lib/MySchema/Result/Aluno.pm
+++ lib/MySchema/Result/Aluno.pm
@@ -40,7 +40,7 @@ __PACKAGE__->has_many(
# Created by DBIx::Class::Schema::Loader v0.04006 @ 2010-03-09 21:13:41
# DO NOT MODIFY THIS OR ANYTHING ABOVE! md5sum:6dR0OXCT5EZN62DTK5cKWw
-
+__PACKAGE__->many_to_many(materias => aluno_materias => 'materia');
# You can replace this text with custom content, and it will be preserved on regeneration
1;
Materia:
--- lib/MySchema/Result/Materia.pm
+++ lib/MySchema/Result/Materia.pm
@@ -35,7 +35,7 @@ __PACKAGE__->has_many(
# Created by DBIx::Class::Schema::Loader v0.04006 @ 2010-03-09 21:13:41
# DO NOT MODIFY THIS OR ANYTHING ABOVE! md5sum:FnsLZ7hmxCmJyjYguAtRdg
-
+__PACKAGE__->many_to_many(alunos => aluno_materias => 'aluno');
# You can replace this text with custom content, and it will be preserved on regeneration
1;
O primeiro argumento de many_to_many indica o nome do relacionamento. O
segundo argumento indica um relacionamento has_many na tabela atual para a
tabela-relacionamento. O terceiro argumento indica o relacionamento
belongs_to na tabela-relacionamento que será utilizado para chegar na segunda
tabela relacionada.
Um script de teste:
diff --git a/source/script/test.pl b/source/script/test.pl
new file mode 100644
index 0000000..04b1243
--- /dev/null
+++ b/source/script/test.pl
@@ -0,0 +1,9 @@
+use warnings;
+use strict;
+use MySchema;
+
+my $schema = MySchema->connect('dbi:Pg:dbname=equinocio_students', 'edenc', '');
+my $estudantes = $schema->resultset('Aluno');
+foreach my $estudante ($estudantes->all) {
+ print ref $estudante, ' => ', $estudante->nome, "\n";
+}
Para executar:
perl -Ilib script/test.pl
O resultado:
MySchema::Result::Aluno => João
MySchema::Result::Aluno => Maria
Percebe-se que o DBIx::Class realizou a consulta e populou os objetos
adequados.
Consultando matérias:
diff --git a/source/script/test.pl b/source/script/test.pl
index 07e3395..faed9f7 100644
--- a/source/script/test.pl
+++ b/source/script/test.pl
@@ -6,4 +6,7 @@ my $schema = MySchema->connect('dbi:Pg:dbname=equinocio_students', 'edenc', '');
my $estudantes = $schema->resultset('Aluno');
foreach my $estudante ($estudantes->all) {
print ref $estudante, ' => ', $estudante->nome, "\n";
+ foreach my $materia ($estudante->materias->all) {
+ print "\t", ref $materia, ' => ', $materia->nome, "\n";
+ }
}
MySchema::Result::Aluno => João
MySchema::Result::Materia => Biologia
MySchema::Result::Materia => Matemática
MySchema::Result::Materia => Física
MySchema::Result::Aluno => Maria
MySchema::Result::Materia => Biologia
Observe que o método materias está disponível por conta da declaração
many_to_many em Aluno.
Para melhorar a conveniência de acesso entre turmas e alunos, é necessária a
inclusão de outro relacionamento many_to_many entre aluno e turma
através da tabela-relacionamento aluno_turma. Um detalhe importante é que o
introspectador utiliza inflexão automática em inglês para determinar o nome dos
relacionamentos, como o exemplo está em português, alguns reparos são
necessários:
diff --git a/source/lib/MySchema/Result/Turma.pm b/source/lib/MySchema/Result/Turma.pm
index b6edf19..20c28bf 100644
--- a/source/lib/MySchema/Result/Turma.pm
+++ b/source/lib/MySchema/Result/Turma.pm
@@ -26,7 +26,7 @@ __PACKAGE__->add_columns(
__PACKAGE__->set_primary_key("id");
__PACKAGE__->add_unique_constraint("turma_pkey", ["id"]);
__PACKAGE__->has_many(
- "turma_alunoes",
+ "turma_alunos",
"MySchema::Result::TurmaAluno",
{ "foreign.turma_id" => "self.id" },
);
diff --git a/source/lib/MySchema/Result/Aluno.pm b/source/lib/MySchema/Result/Aluno.pm
index 3444c57..0163c8e 100644
--- a/source/lib/MySchema/Result/Aluno.pm
+++ b/source/lib/MySchema/Result/Aluno.pm
@@ -31,7 +31,7 @@ __PACKAGE__->has_many(
{ "foreign.aluno_id" => "self.id" },
);
__PACKAGE__->has_many(
- "turma_alunoes",
+ "turma_alunos",
"MySchema::Result::TurmaAluno",
{ "foreign.aluno_id" => "self.id" },
);
diff --git a/source/lib/MySchema/Result/TurmaAluno.pm b/source/lib/MySchema/Result/TurmaAluno.pm
index 74cad38..b24509f 100644
--- a/source/lib/MySchema/Result/TurmaAluno.pm
+++ b/source/lib/MySchema/Result/TurmaAluno.pm
@@ -15,8 +15,8 @@ __PACKAGE__->add_columns(
);
__PACKAGE__->set_primary_key("turma_id", "aluno_id");
__PACKAGE__->add_unique_constraint("turma_aluno_pkey", ["turma_id", "aluno_id"]);
-__PACKAGE__->belongs_to("turma_id", "MySchema::Result::Turma", { id => "turma_id" });
-__PACKAGE__->belongs_to("aluno_id", "MySchema::Result::Aluno", { id => "aluno_id" });
+__PACKAGE__->belongs_to("turma", "MySchema::Result::Turma", { id => "turma_id" });
+__PACKAGE__->belongs_to("aluno", "MySchema::Result::Aluno", { id => "aluno_id" });
# Created by DBIx::Class::Schema::Loader v0.04006 @ 2010-03-09 21:13:41
Por fim, a declaração do relacionamento many_to_many:
diff --git a/source/lib/MySchema/Result/Aluno.pm b/source/lib/MySchema/Result/Aluno.pm
index 0163c8e..4353455 100644
--- a/source/lib/MySchema/Result/Aluno.pm
+++ b/source/lib/MySchema/Result/Aluno.pm
@@ -41,6 +41,7 @@ __PACKAGE__->has_many(
# DO NOT MODIFY THIS OR ANYTHING ABOVE! md5sum:6dR0OXCT5EZN62DTK5cKWw
__PACKAGE__->many_to_many(materias => aluno_materias => 'materia');
+__PACKAGE__->many_to_many(turmas => turma_alunos => 'aluno');
# You can replace this text with custom content, and it will be preserved on regeneration
1;
diff --git a/source/lib/MySchema/Result/Turma.pm b/source/lib/MySchema/Result/Turma.pm
index 20c28bf..4ccd20a 100644
--- a/source/lib/MySchema/Result/Turma.pm
+++ b/source/lib/MySchema/Result/Turma.pm
@@ -35,7 +35,7 @@ __PACKAGE__->has_many(
# Created by DBIx::Class::Schema::Loader v0.04006 @ 2010-03-09 21:13:41
# DO NOT MODIFY THIS OR ANYTHING ABOVE! md5sum:yruj1LRVJruSL2miqJFQlA
-
+__PACKAGE__->many_to_many(alunos => turma_alunos => 'aluno');
# You can replace this text with custom content, and it will be preserved on regeneration
1;
diff --git a/source/script/test.pl b/source/script/test.pl
index 8152c51..695b2f8 100644
--- a/source/script/test.pl
+++ b/source/script/test.pl
@@ -3,12 +3,13 @@ use strict;
use MySchema;
my $schema = MySchema->connect('dbi:Pg:dbname=equinocio_students', 'edenc', '');
-my $estudantes = $schema->resultset('Aluno');
-foreach my $estudante ($estudantes->all) {
- print ref $estudante, ' => ', $estudante->nome, "\n";
- foreach my $aluno_materia ($estudante->aluno_materias->all) {
- my $materia = $aluno_materia->materia;
- print "\t", ref $materia, ' => ', $materia->nome, "\n";
- print "\t\t", ref $aluno_materia, ' => ', $aluno_materia->nota, "\n";
+my $turmas = $schema->resultset('Turma');
+foreach my $turma ($turmas->all) {
+ print ref $turma, ' => ', $turma->turma, "\n";
+ foreach my $aluno ($turma->alunos->all) {
+ print "\t", ref $aluno, ' => ', $aluno->nome, "\n";
+ foreach my $materia ($aluno->materias) {
+ print "\t\t", ref $materia, ' => ', $materia->nome, "\n";
+ }
}
}
perl -Ilib script/test.pl
MySchema::Result::Turma => 7ª Série
MySchema::Result::Aluno => João
MySchema::Result::Materia => Biologia
MySchema::Result::Materia => Matemática
MySchema::Result::Materia => Física
MySchema::Result::Turma => 6ª Série
MySchema::Result::Aluno => Maria
MySchema::Result::Materia => Biologia
O DBIx::Class funciona de uma maneira bastante similar ao que implementamos
na classe DAO. As seguintes etapas ocorrem durante uma consulta:
Estabelecimento dos critérios para recuperação dos dados através de SQL ou do
mecanismo de geração de SQL embutido. No exemplo, não houveram critérios
explícitos, porém o DBIx::Class utilizou os meta-dados nos result sources
para induzir critérios implicitamente.
my $turmas = $schema->resultset('Turma');
Indica que todos os registros da tabela turma devem ser recuperados. O valor
que passamos como argumento é o nome do result source, que reside na classe
MySchema::Result::Turma. Não é necessário indicar o nome completo da classe.
$turma->alunos;
Indica que todos os registros relacionados àquele objeto específico devem ser
recuperados. O DBIx::Class utiliza os meta-dados fornecidos na definição do
relacionamento para construir o join com um critério adequado e recuperar os
dados na tabela correta. Uma forma equivalente de se obter o mesmo conjunto de
registros seria construir o critério manualmente:
$schema->resultset('TurmaAluno')
->search({ turma_id => $turma->id })
->related_resultset('aluno');
O critério é bastante parecido com o que está definido no relacionamento.
Porém, utilizar a definição do relacionamento é mais eficiente do ponto de
vista de engenharia porque mantém o critério canonizado em um único lugar,
facilitando o processo de manutenção.
Os detalhes de funcionamento dos métodos search e related_resultset serão
abordados mais adiante junto com a definição do conceito de Result Set.
O DBIx::Class tenta otimizar o processo de consultas o máximo possível. As
consultas são realizadas de maneira "preguiçosa", isso significa que só haverá
execução quando os dados forem realmente necessários e não durante o processo
de definição da consulta. Por exemplo, a consulta que recupera a lista de
turmas não acontece durante a chamada a $schema-resultset('Turma')>, mas
durante a chamada a $turmas-all>. Isso é um conceito fundamental, porque
talvez fosse necessário o acréscimo de critérios extras antes da realização da
consulta.
Uma outra otimização que ocorre na recuperação dos dados é o caching automático
dos resultados. A consulta só ocorre na primeira vez em que acontece a chamada
$turmas-all>, uma segunda invocação irá utilizar os dados cacheados. O mesmo
vale para os objetos $turma individuais, não acontecem consultas adicionais
a cada vez que se invoca $turma-turma>, por exemplo.
Os handles de consultas do DBI também são cacheados, portanto há um pequeno
ganho de desempenho em relação à implementação do DAO, que prepara um novo
handle, mesmo sendo uma repetição da mesma consulta. Além do cache, ocorre uma
verificação da conexão com o banco, se houver uma falha na comunicação, o
DBIx::Class irá automaticamente tentar re-estabelecer a conexão antes de
executar a consulta.
Os dados recuperados por uma consulta são sempre fornecidos pelo backend de forma tabular, o que requer um trabalho de re-estruturação durante a população dos objetos. Por exemplo, a consulta para recuperar todos os alunos e suas respectivas matérias seria:
SELECT aluno.id,
aluno.nome,
aluno_materias.aluno_id,
aluno_materias.materia_id,
aluno_materias.nota,
materia.id,
materia.nome
FROM turma_aluno me
JOIN aluno aluno ON aluno.id = me.aluno_id
LEFT JOIN aluno_materia aluno_materias ON aluno_materias.aluno_id = aluno.id
LEFT JOIN materia materia ON materia.id = aluno_materias.materia_id
E o resultado seria:
id | nome | aluno_id | materia_id | nota | id | nome
----+-------+----------+------------+------+----+------------
1 | João | 1 | 1 | | 1 | Biologia
1 | João | 1 | 2 | | 2 | Matemática
1 | João | 1 | 3 | | 3 | Física
2 | Maria | 2 | 1 | | 1 | Biologia
Existem 3 registros contendo os dados de um único registro em aluno, devido ao
produto cartesiano resultante do join. É desejável que apenas um objeto aluno
equivalente ao registro João exista na aplicação para esse caso. O que
permite exibir a hierarquia dos dados sem repetições como acontece no exemplo.
Baseado nos meta-dados presentes nas classes Result Source, o DBIx::Class
consegue re-estruturar os dados tabulares mapeando-os para objetos
estruturados. Esse processo se chama "colapso de dados", devido ao processo
de destruição de dados duplicados que acontece por trás das cenas.
O processo de "inflar" dados ocorre quando dados passam do backend para a
aplicação, o sentido inverso se chama "deflação". Na implementação exemplar
da classe DAO, a inflação foi feita manualmente. O DBIx::Class fornece um
mecanismo de inflação extensível que, por padrão, constrói objetos da mesma
classe que o Result Source, como por exemplo MySchema::Result::Aluno. Esses
objetos herdam da classe DBIx::Class::Row que fornece operações sobre dados
de um único registro. O processo de inflação pode ser alterado através da
sobrecarga do método inflate_result em qualquer classe Result Source. Por
exemplo, se fosse desejável construir hashes invés de objetos
MySchema::Result::Materia:
diff --git a/source/lib/MySchema/Result/Materia.pm b/source/lib/MySchema/Result/Materia.pm
index c6ce5d8..401a1bd 100644
--- a/source/lib/MySchema/Result/Materia.pm
+++ b/source/lib/MySchema/Result/Materia.pm
@@ -37,6 +37,11 @@ __PACKAGE__->has_many(
__PACKAGE__->many_to_many(alunos => aluno_materias => 'aluno');
+sub inflate_result {
+ my($self, $source, $data) = @_;
+ return $data;
+}
+
# You can replace this text with custom content, and it will be preserved on regeneration
1;
diff --git a/source/script/test.pl b/source/script/test.pl
index 695b2f8..377fffe 100644
--- a/source/script/test.pl
+++ b/source/script/test.pl
@@ -1,6 +1,7 @@
use warnings;
use strict;
use MySchema;
+use Data::Dump;
my $schema = MySchema->connect('dbi:Pg:dbname=equinocio_students', 'edenc', '');
my $turmas = $schema->resultset('Turma');
@@ -9,7 +10,7 @@ foreach my $turma ($turmas->all) {
foreach my $aluno ($turma->alunos->all) {
print "\t", ref $aluno, ' => ', $aluno->nome, "\n";
foreach my $materia ($aluno->materias) {
- print "\t\t", ref $materia, ' => ', $materia->nome, "\n";
+ print "\t\t", ref $materia, ' => ', Data::Dump::dump($materia), "\n";
}
}
}
JSON invés de hash:
diff --git a/source/lib/MySchema/Result/Materia.pm b/source/lib/MySchema/Result/Materia.pm
index 401a1bd..982d538 100644
--- a/source/lib/MySchema/Result/Materia.pm
+++ b/source/lib/MySchema/Result/Materia.pm
@@ -2,6 +2,7 @@ package MySchema::Result::Materia;
use strict;
use warnings;
+use JSON ();
use base 'DBIx::Class';
@@ -39,7 +40,7 @@ __PACKAGE__->many_to_many(alunos => aluno_materias => 'aluno');
sub inflate_result {
my($self, $source, $data) = @_;
- return $data;
+ return JSON::to_json($data);
}
# You can replace this text with custom content, and it will be preserved on regeneration
diff --git a/source/script/test.pl b/source/script/test.pl
index 377fffe..45590cb 100644
--- a/source/script/test.pl
+++ b/source/script/test.pl
@@ -10,7 +10,7 @@ foreach my $turma ($turmas->all) {
foreach my $aluno ($turma->alunos->all) {
print "\t", ref $aluno, ' => ', $aluno->nome, "\n";
foreach my $materia ($aluno->materias) {
- print "\t\t", ref $materia, ' => ', Data::Dump::dump($materia), "\n";
+ print "\t\t", ref $materia, ' => ', $materia, "\n";
}
}
}
Até agora, foram abordados exemplos básicos de consultas e recuperação de dados. Porém, efetuar consultas de forma manutenível e reaproveitável não é uma tarefa fácil. Suponha a seguinte lista de requisitos e o SQL equivalente:
SELECT * FROM aluno;
SELECT * FROM aluno me
JOIN turma_aluno ta
ON ta.aluno_id = me.id
WHERE ta.turma_id = ?;
SELECT * FROM aluno me
JOIN aluno_materia ma
ON ma.aluno_id = me.id
WHERE ma.materia_id = ?;
Uma outra forma de enxergar um requisito desses é através de conjuntos:
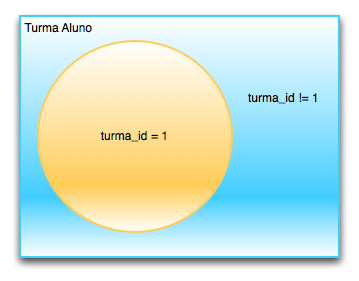
Em DBIx::Class nós expressamos esses conjuntos através de objetos Result Set:
my $alunos = $schema->resultset('Aluno');
$alunos contém o conjunto universo dos registros de alunos, ou seja, todos
os alunos.
my $alunos_turma1 = $alunos->search(
{ 'turma_alunos.turma_id' => 1 },
{ join => [qw(turma_alunos)] }
);
$alunos_turma1 é um subconjunto de $alunos, que contém registros dos
alunos da turma 1. Como a informação de relacionamento entre turmas está na
tabela-relacionamento turma_aluno, é necessária a declaração de um join com
o relacionamento equivalente.
Para maior conveniência de abstração, podem ser criados métodos no Result Set equivalente:
diff --git a/source/lib/MySchema/ResultSet/Aluno.pm b/source/lib/MySchema/ResultSet/Aluno.pm
new file mode 100644
index 0000000..0163cbf
--- /dev/null
+++ b/source/lib/MySchema/ResultSet/Aluno.pm
@@ -0,0 +1,23 @@
+package MySchema::ResultSet::Aluno;
+use warnings;
+use strict;
+
+use base 'DBIx::Class::ResultSet';
+
+sub turma {
+ my($self, $turma_id) = @_;
+ return $self->search(
+ { 'turma_alunos.turma_id' => $turma_id },
+ { join => [qw(turma_alunos)] }
+ );
+}
+
+sub materia {
+ my($self, $materia_id) = @_;
+ return $self->search(
+ { 'aluno_materias.materia_id' => $materia_id },
+ { join => [qw(aluno_materias)] }
+ );
+}
+
+1;
O método search é um construtor de objetos Result Set, cada invocação desse
método cria um clone do conjunto original e acrescenta os parâmetros passados.
O primeiro argumento, é uma referêcia para um hash especificando o critério de
seleção de registros, caso anterior, deseja-se utilizar um critério sobre uma
tabela relacionada, nesse caso, se utiliza o nome do relacionamento, a exemplo
de aluno_materias.materia_id. O segundo hash, são atributos passados para o
Result Set, nesse caso, indicando o join desejado.
diff --git a/source/script/test.pl b/source/script/test.pl
index 377fffe..3e21ffa 100644
--- a/source/script/test.pl
+++ b/source/script/test.pl
@@ -4,13 +4,7 @@ use MySchema;
use Data::Dump;
my $schema = MySchema->connect('dbi:Pg:dbname=equinocio_students', 'edenc', '');
-my $turmas = $schema->resultset('Turma');
-foreach my $turma ($turmas->all) {
- print ref $turma, ' => ', $turma->turma, "\n";
- foreach my $aluno ($turma->alunos->all) {
- print "\t", ref $aluno, ' => ', $aluno->nome, "\n";
- foreach my $materia ($aluno->materias) {
- print "\t\t", ref $materia, ' => ', Data::Dump::dump($materia), "\n";
- }
- }
+my $alunos = $schema->resultset('Aluno')->turma(1);
+foreach my $aluno ($alunos->all) {
+ print "\t", ref $aluno, ' => ', $aluno->nome, "\n";
}
Mais detalhes sobre o método search podem ser encontrados na documentação da
classe DBIx::Class::ResultSet.
Eventualmente surgirão formas desejáveis de se combinar os resultados anteriores, por exemplo, enumerar alunos cursando uma determinada matéria em uma turma.
SELECT * FROM aluno me
JOIN turma_aluno ta ON ta.aluno_id = me.id
JOIN aluno_materia ma
ON ma.aluno_id = me.id
WHERE ta.turma_id = ?
AND ma.materia_id = ?;
Como cada invocação de search retorna um novo subconjunto, pode-se encadear
invocações para combinar os critérios das chamadas.
diff --git a/source/script/test.pl b/source/script/test.pl
index 3e21ffa..68df674 100644
--- a/source/script/test.pl
+++ b/source/script/test.pl
@@ -4,7 +4,7 @@ use MySchema;
use Data::Dump;
my $schema = MySchema->connect('dbi:Pg:dbname=equinocio_students', 'edenc', '');
-my $alunos = $schema->resultset('Aluno')->turma(1);
+my $alunos = $schema->resultset('Aluno')->turma(1)->materia(2);
foreach my $aluno ($alunos->all) {
print "\t", ref $aluno, ' => ', $aluno->nome, "\n";
}
Não é necessária a escrita de SQL ou consultas adicionais, apenas foram
reaproveitados métodos que já existiam antes e que puderam ser combinados pela
arquitetura de consultas do DBIx::Class. Pelo fato das consultas serem
preguiçosas, a consulta não ocorre durante a invocação de turma ou
materia, apenas quando se invoca all, e nesse ponto, os critérios da
consulta foram populados pelos métodos anteriores.
O fato de que cada invocação de search constrói um novo conjunto permite o
reaproveitamento dos objetos result set. Por exemplo:
my $alunos_turma1 = $schema->resultset('Alunos')->turma(1);
my $alunos_turma1_aprovados = $alunos_turma1->search(
{ 'materia_alunos.nota' => { '>' => 7 } },
{ join => [qw(materia_alunos)] }
);
my $alunos_turma1_materia1 = $alunos_turma1->materia(1);
my $alunos_turma1_materia1_aprovados->materia(1);
Observando a forma como as aplicações interagem com bases de dados, fica óbvio
que o principal problema de se escrever uma camada intermediária é alcançar um
contrato flexível, tanto com a aplicação quanto com a base de dados. O
DBIx::Class tenta se destacar dos outros ORMs através do fornecimento de
uma arquitetura formal porém flexível, e que tem opções de extensibilidade
convenientes. O DBIx::Class se propõe muito mais a ser um framework de
construção de camadas de acesso a dados do que um ORM propriamente dito.
Hoje abordamos alguns princípios fundamentais sobre camadas de acesso a dados
baseadas em DBIx::Class, assim como algumas funcionalidades básicas de
arquitetura e construção de consultas. Amanhã serão abordadas formas avançadas
de consulta e escrita, além de técnicas de desenvolvimento e depuração.
Eden Cardim <edencardim@gmail.com> é consultor de perl independente há 4 anos, trabalha com perl desde 1998 e é contribuidor dos projetos DBIx::Class, Catalyst e Reaction, além de contribuidor do CPAN. Atualmente, presta serviço para a ShadowCat System Ltd.