
Hernan LopesPublicado em 01/03/2011
Este artigo tem como objetivo proporcionar um exemplo prático que envolva:
- Utilização de Crawlers/Spider para automatizar a navegação em sites com perl.
- Xpath para determinar onde estão os dados que procuramos dentro de uma página web.
- Expressões regulares para re-formatar strings de conteúdo de acordo com o que precisamos.
- Exportar dados do site em arquivo formato ODF ( openoffice spreadsheets ).
Para começar escolheremos um site como ponto de partida. Acesse a url escolhida para nosso artigo: http://www.portaltransparencia.gov.br/despesasdiarias/resultado?consulta=rapida&periodoInicio=01%2F01%2F2011&periodoFim=31%2F01%2F2011&fase=EMP&códigoOS=51000&códigoFavorecido= Obs: para obter esta url, acessei o site http://www.portaltransparencia.gov.br/despesasdiarias e selecionei o período de 01/01/2011 a 31/01/2011, Empenho, Ministério do esporte > consultar.
Esta é uma página do portal da transparência. O que vamos fazer agora é analisar alguns pontos importantes de uma página:
- possui paginação?
- formatação dos dados, valores, strings, etc. observe os padrões dos dados para poder criar regex e arrumar os dados de acordo.
- layout da página. como os dados estão dispostos ? é uma tabela? são divs? onde estão os dados que eu preciso em uma determinada página ?
Observe a página e note que ela possui paginação e tem os dados formatados em uma table. Com esta informação já é possível perceber que teremos que acessar cada página e ler os dados que estão dentro da tabela. Quanto à formatação dos dados, navegando em algumas páginas é possível notar que os preços muito provavelmente precisarão ser re-formatados para que o banco de dados os aceite como valores válidos.
Para acessar estes dados utilizarei XPath, que é uma sintaxe utilizada para navegar entre atributos e elementos em um documento xml. XPath está presente e é utilizado nas mais diversas linguagens de programação. Sua sintaxe é similar a: "//html/body/div/span" que retornaria o valor do texto que está dentro do span. Leia mais sobre xpath em http://www.w3schools.com/xpath/default.asp
Exemplos de notação XPath:
- //td[1] : retorna o primeiro
- //td[position()=1] : retorna o primeiro
- //table[@class='tabelao'] : retorna a table com class = 'tabelao'
- //table/td[1] : retorna o primeiro td de uma
- /body/html//table/td[1] : retorna o primero td de uma tabela dentro do
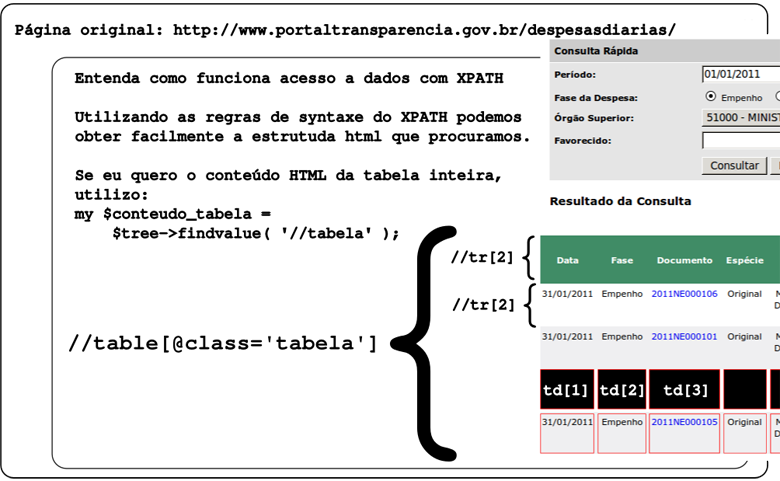
Agora que entendemos o básico sobre XPath, vamos continuar e aplicar este aprendizado no site que escolhemos anteriormente. O objetivo vai ser carregar os dados da página dentro de uma estrutura de dados criada especificamente para este site. Veja a ilustração do que deve ser feito conforme a imagem:
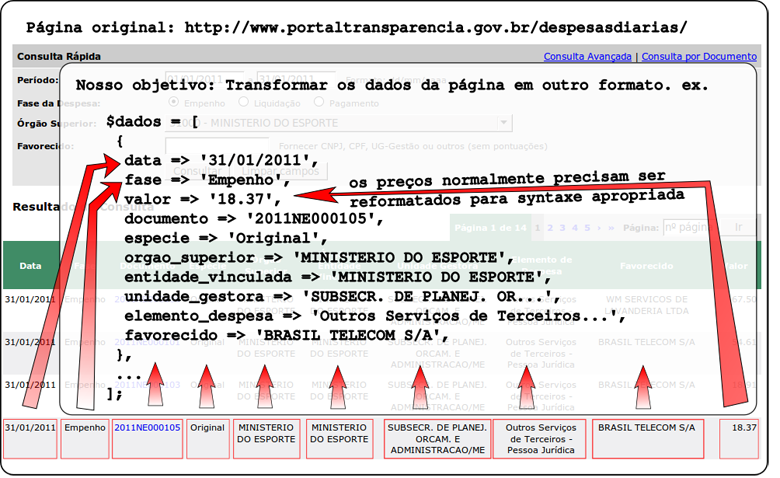
Depois que obtivermos os dados, eles serão parseados e será feita uma re-formatação em alguns deles. O objetivo desta reformatação é adaptá-los aos formatos necessários para nós. Para isto vamos utilizar Expressões regulares com o objetivo de analisar todo o conteúdo obtido e transformá-lo de acordo com o que precisamos. Obs. isto pode ser feito já na hora da leitura dos dados. Veja 2 exemplos de como aplicar regex em um texto:
use strict;
use warnings;
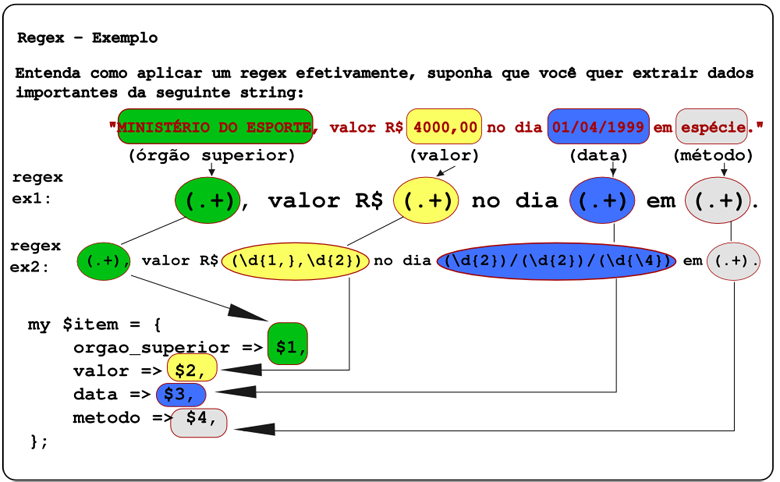
my $string = 'Ministerio do esporte, valor R$ 4000,00 no dia 01/02/1999 em espécie.';
$string =~ m/(.+), valor R\$ (.+) no dia (.+) em (.+)./ ;
print $1,"\n";
print $2,"\n";
print $3,"\n";
print $4,"\n";
print "-------","\n";
$string =~ m/(.+), valor R\$ (\d{1,},\d{2}) no dia (\d{2})\/(\d{2})\/(\d{4}) em (.+)./ ;
print $1,"\n";
print $2,"\n";
print $3, '/', $4, '/', $5,"\n";
print $6,"\n";
print "-------","\n";
Veja um exemplo de regex na imagem:
Compilei uma tabela de regex simples com os itens que mais utilizo quando trabalho com regex:
Tabela de regex simples [A-Za-z0-9] Apenas caracteres alfanuméricos
[A-Za-z0-9_] Alfanuméricos e _
\w Alfanuméricos e _
[0-9] Apenas dígitos
\d Apenas dígitos
\D Não dígitos
\s espaço
\S Não espaço
^ String começando em
$ String terminando em
[^a-zA-Z0-9_] Negação/Não alfanuméricos
\n Nova linha
\r Carriage return
{min,max} Quantidade de ocorrências
() Agrupa itens dentro do parêntesis
| Separa alternativas
. Algum caracter
(.+) Alguma coisa obrigatoriamente
(.*) Alguma coisa opcionalmente
Um ótimo módulo para fazer este tipo de trabalho é:
OpenOffice::OODoc
No entanto após algumas tentativas eu não consegui colocar os dados que eu obtive logo na tabela (spreadsheet) inicial do arquivo... então eu criei uma nova tabela dentro do meu arquivo openoffice e ai sim consegui salvar os dados por completo. Segue o exemplo do código implementado:
sub exportar_e_salvar_odf {
my ( $items ) = @_;
my $document = odfDocument(file => 'portal_transparencia.ods', create => 'spreadsheet');
my $table = $document->appendTable("TABELA DADOS", 1000,50);
my $line = 0;
my $all_fields = get_fields();
my $col = 0;
foreach my $field ( qw/data fase documento especie orgao_superior entidade_vinculada unidade_gestora elemento_despesa favorecido valor/ ) {
$document->updateCell( $table, $line, $col++, $all_fields->{ $field }->{ label } );
}
foreach my $item ( @$items ) {
$line++;
$col = 0;
foreach my $field ( qw/data fase documento especie orgao_superior entidade_vinculada unidade_gestora elemento_despesa favorecido valor/ ) {
$document->updateCell( $table, $line, $col++, $item->{ $field } );
}
}
$document->save;
}
E agora finalmente vamos aplicar tudo isto no código e gerar um arquivo de saída spreadsheet ods (open office). Este código tem por objetivo baixar todos os dados da página do ministério dos esportes (veja o início do artigo).
#!/usr/bin/perl
use strict;
use warnings;
use WWW::Mechanize;
use HTML::TreeBuilder::XPath;
use HTML::LinkExtor;
use OpenOffice::OODoc;
my $mech = WWW::Mechanize->new();
$mech->agent_alias( 'Windows IE 6' );
my $url = 'http://www.portaltransparencia.gov.br/despesasdiarias/resultado'.
'?consulta=rapida&periodoInicio=01%2F01%2F2011&periodoFim=31%2F01%2F2011'.
'&fase=EMP&códigoOS=51000&códigoFavorecido=';
my @items = ();
my $url_visited = {};
scan_page( $url );
@items = reformata_dados_com_regex( \@items );
exportar_e_salvar_odf( \@items );
use Data::Dumper;
print "Resultados","\n", Dumper @items, "\n";
print "Para ver o arquivo em formato openoffice, abra o arquivo criado: \n";
print "'portal_transparencia.ods' e veja a tabela de nome 'TABELA DADOS'\n";
sub scan_page {
my ( $link ) = @_;
$mech->get( $link );
my @links_paginacao = search_links_paginacao(
$mech->res->content, '//p[@id="paginacao"]'
);
foreach my $url ( @links_paginacao ) {
if ( ! $url_visited->{ $url } ) {
print "Acessando url: ", $url, "\n";
$mech->get( $url );
my $pagina_html = $mech->res->content;
parse_data( $pagina_html );
$url_visited->{ $url } = 'visited';
scan_page( $url );
} else {
# print "url visitada","\n";
}
}
}
sub search_links_paginacao {
my ( $html, $pagination_xpath ) = @_;
my $tree= HTML::TreeBuilder::XPath->new;
$tree->parse( $html );
my $pagination_div = $tree->findnodes( $pagination_xpath );
$pagination_div = $pagination_div->[0]->as_HTML;
my $url_list = HTML::LinkExtor->new();
$url_list->parse( $pagination_div );
my @links= ();
foreach my $item ( @{ [ $url_list->links ] } ) {
push( @links, 'http://www.portaltransparencia.gov.br' . @$item[2]);
}
$tree->delete;
return @links;
}
sub parse_data {
my ( $html ) = @_;
my $tree= HTML::TreeBuilder::XPath->new;
$tree->parse( $html );
my $tabela = $tree->findnodes( '//table[@class="tabela"]' );
my $tabela_com_dados_html = $tabela->[0]->as_HTML; #
my $table_rows = $tree->findnodes( '//table[@class="tabela"]/tr' );
my $count = 0;
foreach my $row ( $table_rows->get_nodelist ) {
if ( $count > 1 ){
my $tree_tr = HTML::TreeBuilder::XPath->new;
$tree_tr->parse( $row->as_HTML );
my $row_data = {
data => $tree_tr->findvalue( '//td[1]' ),
fase => $tree_tr->findvalue( '//td[2]' ),
documento => $tree_tr->findvalue( '//td[3]' ),
especie => $tree_tr->findvalue( '//td[4]' ),
orgao_superior => $tree_tr->findvalue( '//td[5]' ),
entidade_vinculada => $tree_tr->findvalue( '//td[6]' ),
unidade_gestora => $tree_tr->findvalue( '//td[7]' ),
elemento_despesa => $tree_tr->findvalue( '//td[8]' ),
favorecido => $tree_tr->findvalue( '//td[9]' ),
valor => $tree_tr->findvalue( '//td[10]' ),
};
push( @items, $row_data );
$tree_tr->delete;
}
$count++;
}
$tree->delete;
}
sub reformata_dados_com_regex {
my ( $items ) = @_;
for ( my $i = 0; $i { data } = join ( '/', $1, $2, $3 )
if ( @$items[$i]->{ data } =~ m/^(\d{4})-(\d{2})-(\d{2})/ ) ;
#4dígitos traço 2 dígitos traço 2 dígitos
@$items[$i]->{ valor } = join ( '.', $1, $2 )
if ( @$items[$i]->{ valor } =~ m/(\d{1,})\.(\d{2})(\d{2})$/ );
#ao menos 1 dígito seguido de . e 2 dígitos de precisão.
}
return @$items;
}
sub exportar_e_salvar_odf {
my ( $items ) = @_;
my $document = odfDocument(
file => 'portal_transparencia.ods',
create => 'spreadsheet');
my $table = $document->appendTable("TABELA DADOS", 1000,50);
my $line = 0;
my $all_fields = get_fields();
my $col = 0;
foreach my $field ( qw/data fase documento especie orgao_superior entidade_vinculada unidade_gestora elemento_despesa favorecido valor/ ) {
$document->updateCell( $table, $line, $col++, $all_fields->{ $field }->{ label } );
}
foreach my $item ( @$items ) {
$line++;
$col = 0;
foreach my $field ( qw/data fase documento especie orgao_superior entidade_vinculada unidade_gestora elemento_despesa favorecido valor/ ) {
$document->updateCell( $table, $line, $col++, $item->{ $field } );
}
}
$document->save;
}
sub get_fields {
my ( $self ) = @_;
return {
data => {
field => 'data',
label => 'Data',
},
fase => {
field => 'fase',
label => 'Fase',
},
documento => {
field => 'documento',
label => 'Documento',
},
especie => {
field => 'especie',
label => 'Espécie',
},
orgao_superior => {
field => 'orgao_superior',
label => 'Órgão Superior',
},
entidade_vinculada => {
field => 'entidade_vinculada',
label => 'Entidade Vinculada',
},
unidade_gestora => {
field => 'unidade_gestora',
label => 'Unidade Gestora',
},
elemento_despesa => {
field => 'elemento_despesa',
label => 'Elemento Despesa',
},
favorecido => {
field => 'favorecido',
label => 'Favorecido',
},
valor => {
field => 'valor',
label => 'Valor',
},
};
}
Hernan Lopes <hernanlopes@gmail.com>